

1. Persistenz der Daten
Wie wir bereits definiert haben, besteht unsere API aus einer Haupteinheit – VedaVersumCard. Unsere Anwendung dient dazu, die Liste der Wissenskarten zu führen und den Nutzern die Möglichkeit zu geben, diese Karten zu erstellen, zu lesen und zu bearbeiten. Um dies zu ermöglichen, haben wir eine Mutation und 3 Abfragen in unserer API definiert. Die Mutation „CardAction“ soll die Kartendaten als Argument nehmen und diese Daten irgendwo speichern. Die Abfrage „allCards“ soll die Liste aller vorhandenen Karten zurückgeben. Die Abfrage „card“ sollte eine Karte nach Karten-ID zurückgeben, und die Abfrage „allCardsAssignedToUser“ sollte die Benutzer-E-Mail als Eingabe nehmen und Karten zurückgeben, die nach der Eigenschaft „assignedUsers“ gefiltert sind, deren Wert dem eingegebenen Benutzer entspricht.

VedaVersum card entity
Im Moment sind diese Mutation und die 3 Abfragen noch nicht implementiert und führen keine relevanten Aktionen mit unserer Entität durch. Nun ist es an der Zeit, die Datenbank zu wählen, in der unsere Kartenliste gespeichert werden soll. Wir haben hier viele Möglichkeiten. Wir können eine relationale Datenbank wie Oracle oder MS SQL Server verwenden. Aber das sind Industriegiganten, die unter hoher Last arbeiten und Hunderte von Transaktionen pro Sekunde durchführen. Das leichtgewichtige SQLite ist eher für kleine Anwendungen geeignet. Die wichtigsten Vorteile von SQLite sind folgende:
- es ist kostenlos und quelloffen
- Es speichert die Daten in einer einzigen Datei und benötigt keinen Server, auf dem die Datenbank-Engine läuft.
- dotNet verfügt über ein hervorragendes Werkzeug für die Arbeit mit relationalen Datenbanken namens Entity Framework.
Andererseits erfordert SQLite, wie jede relationale Datenbank, die Definition eines stark typisierten Datenbankschemas. Zum Beispiel können wir in unserer VedaVersum-Entität in Zukunft einige andere Eigenschaften wie das Flag „Archiviert“ definieren. Im Falle einer relationalen Datenbank ist dies eine einschneidende Änderung, die einige Anstrengungen erfordert, um Schemamigrationen mit bereits bestehenden Datenbanken zu ermöglichen. Sie sind gerechtfertigt, wenn wir ein reichhaltiges, gut strukturiertes, denormalisiertes Datenmodell haben, das sich nicht allzu oft ändert. Aber in unserem Fall sind die VedaVersum-Entitäten nur eine Liste von Dokumenten. NoSQL-Datenbanken sind die perfekte Datenbank, um Listen von Dokumenten zu speichern. Aus diesem Grund werden wir MongoDB verwenden. Dies ist der Hauptakteur in der Welt der NoSQL-Datenbanken. Sie ist kostenlos und Open-Source. Sie speichert Daten als Liste von JSON-Dokumenten und benötigt kein stark typisiertes Datenbankschema. Außerdem bietet sie wie alle seriösen Datenbanken hohe Leistung, Skalierung und Backup-Tools.
2.1. MongoDB einrichten
Wenn Sie noch nie Mongo in Ihrem Entwicklungssystem verwendet haben, sollten Sie zuerst die Datenbank-Engine installieren. Hier sind einige Anweisungen, wie Sie dies tun können. Ich verwende Docker Desktop auf meinem Rechner und habe MongoDB als Docker-Container gestartet.
Sobald wir die MongoDB-Engine zum Laufen gebracht haben, können wir sie in unserem Projekt verwenden. Es gibt einen MongoDB-Treiber für DotNet, den wir in unserem Projekt verwenden werden, also sollten wir zuerst ein Nuget-Paket zu unserem Projekt hinzufügen.
Zweitens sollten wir einen neuen Parameter zu unserer appsettings.json mit der Verbindungszeichenfolge hinzufügen.
Und drittens sollten wir eine neue Schnittstelle IVedaVersumDataAccess und einen VedaVersumDataAccess-Dienst definieren, der diese Schnittstelle implementiert.

2.2. Implementierung des Datenzugriffs
Wir haben die Datenzugriffsschnittstelle mit CRUD-Operationen definiert. Wir werden diese Schnittstelle in unseren Mutationen und Abfragen verwenden. Und hier beschreibe ich kurz die Implementierung des Datenzugriffs selbst.
"ConnectionStrings": {
"mongo": "mongodb://localhost:27017"
}
public class VedaVersumDataAccess : IVedaVersumDataAccess
{
private const string DatabaseName = "VedaVersum";
private const string VedaVersumCardsCollectionName = "Cards";
private readonly IMongoDatabase _database;
public VedaVersumDataAccess(string mongoDbConnectionString, ILogger<VedaVersumDataAccess> logger)
{
var mongoConnectionUrl = new MongoUrl(mongoDbConnectionString);
var mongoClientSettings = MongoClientSettings.FromUrl(mongoConnectionUrl);
mongoClientSettings.ClusterConfigurator = cb => {
cb.Subscribe<CommandStartedEvent>(e => {
logger.LogDebug($"{e.CommandName} - {e.Command.ToJson()}");
});
};
var client = new MongoClient(mongoClientSettings);
_database = client.GetDatabase(DatabaseName);
}
/// <inheritdoc />
public async Task DeleteCard(string cardId)
{
var cardsCollection = _database.GetCollection<VedaVersumCard>(VedaVersumCardsCollectionName);
await cardsCollection.DeleteOneAsync(Builders<VedaVersumCard>.Filter.Where(c => c.Id == cardId));
}
/// <inheritdoc />
public async Task<IEnumerable<VedaVersumCard>> GetAll()
{
var cardsCollection = _database.GetCollection<VedaVersumCard>(VedaVersumCardsCollectionName);
var allCards = await cardsCollection.FindAsync(Builders<VedaVersumCard>.Filter.Empty);
return allCards.ToList();
}
// Code omitted for brevity
}
startup.cs
// DataAccess
var connectionString = Configuration.GetConnectionString("mongo");
services.AddTransient<IVedaVersumDataAccess, VedaVersumDataAccess>((p) => new VedaVersumDataAccess(
connectionString,
p.GetService<ILogger<VedaVersumDataAccess>>()!));
Den vollständigen Code finden Sie im GitHub-Repository. Wie Sie sehen können, ist es ziemlich einfach, MongoDB in ASP.Net Core-Anwendungen zu verwenden. Und hier sind unsere API-Methoden in Betrieb:
Create Card:

Read All Cards:

Update card:

Wir haben die Datenpersistenz in unserer Anwendung implementiert! Juhu!
3. GraphQL resolvers und data loaders
Nun ist es an der Zeit, ein wenig über die Querverweise zwischen Datenobjekten und die Leistung zu sprechen. Wie Sie bereits bemerkt haben, verfügt jede knowledge card über eine Liste von zugehörigen card Ids. Die Karten werden in der Datenbank mit dieser Struktur gespeichert:
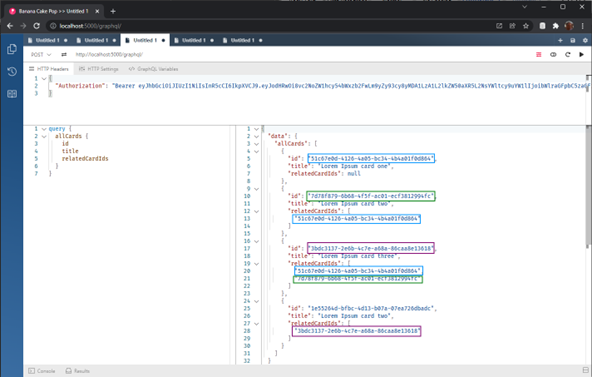
So verweist „card two“ auf „card on“, „card three“ auf „card two und one“ und so weiter. Wenn wir alle Karten abrufen, ist das vielleicht kein großes Problem. Aber was ist, wenn die Client-Anwendung nur die „card three“ und alle ihre Abhängigkeiten abrufen möchte, sieht unsere Abfrage wie folgt aus:
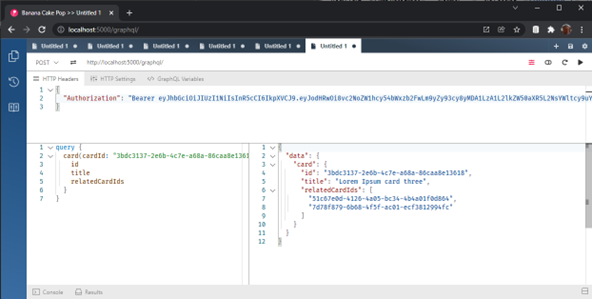
Für verwandte Karten haben wir nur Ids, und um deren Inhalt zu erhalten, muss der Client dieselbe Abfrage zwei weitere Male aufrufen. Und wenn es mehr als zwei verwandte Karten gibt, steigt die Anzahl der Anfragen vom Client an den Server dramatisch an. Diese Situation ist bei REST-API üblich und wird als „n+1-Problem“ bezeichnet.
Glücklicherweise ist eine der Aufgaben von GraphQL, dieses n+1 Problem zu beseitigen. Wir können einen Abfrage-Hook namens Resolver definieren. Dieser Resolver ermöglicht es dem Client, alle verwandten Objekte mit einer Anfrage abzurufen. Fügen wir diesen Resolver zu unserer GraphQL-API für verwandte Karten hinzu:
public class VedaVersumCardObjectType: ObjectType<VedaVersumCard>
{
protected override void Configure(IObjectTypeDescriptor<VedaVersumCard> descriptor)
{
descriptor
.Field("relatedCards") // Name of the additional field
.Type<ListType<VedaVersumCardObjectType>>()
.Resolve(async context =>
{
var parent = context.Parent<VedaVersumCard>();
if(parent.RelatedCardIds == null || parent.RelatedCardIds.Count == 0)
{
return new List<VedaVersumCard>();
}
var dataAccess = context.Service<IVedaVersumDataAccess>();
return await dataAccess.GetCardsById(parent.RelatedCardIds);
});
}
}
Dieser Objekttyp erweitert unser VedaVersumCard-Objekt und fügt ihm ein neues Feld hinzu. Und implementiert die Logik zum Füllen dieses Feldes. Nun müssen wir diese neue Objekttyp-Definition zu unserem GraphQL-Server-Setup in startup.cs hinzufügen.
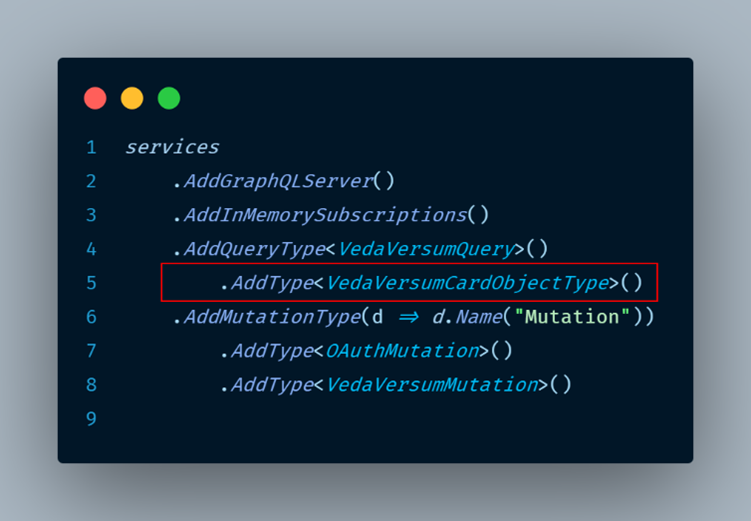
Und wir können unsere Abfrage erneut ausführen:

Wie Sie feststellen konnten, gibt es ein zusätzliches Feld in der Abfrage namens „relatedCards“, und wir können alle Informationen zu verwandten Karten mit einer einzigen Anfrage an den GraphQL-Server abrufen. Wir sind also unser n+1 Problem losgeworden. Bingo!
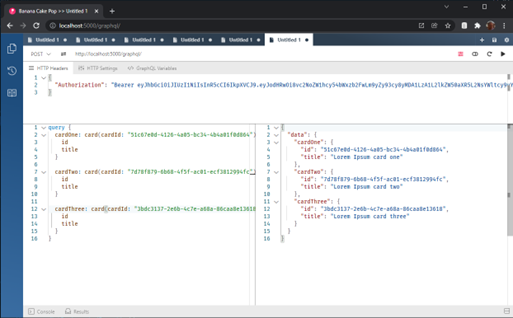
Es gibt noch einen weiteren Punkt. GraphQL ermöglicht sowohl die Abfrage zusammengehöriger Daten durch eine einzige Anfrage als auch die Konstruktion der Anfrage so, dass dieselbe API-Methode mehrfach mit unterschiedlichen Parametern, aber mit nur einer Anfrage aufgerufen werden kann. Ein Beispiel: Die Client-Anwendung hat die IDs von drei Karten. Der Kunde kann die Abfrage so konstruieren, dass er die Details aller 3 Karten mit dieser Abfrage erhält:

Es funktioniert perfekt. Ich kann alle Daten abrufen, die ich will, ohne das oben erwähnte n+1-Problem. Aber wenn ich neugierig wäre und einen Logger an den MongoDB-Client anhängen würde, könnte ich sehen, dass der GraphQL-Server mit dieser einen Anfrage 3 nachfolgende Anfragen an die Datenbank gestellt hat.

Werfen wir noch einmal einen Blick auf unsere Abfragemethode:
/// <summary>
/// Returns card by ID
/// </summary>
public async Task<VedaVersumCard?> GetCardById(string cardId)
{
return _dataAccess.GetCardById(cardId);
}
Trotz der einzigen Abfrage an GraphQL wird der Resolver jedes Mal für jede ID ausgeführt. Und jedes Mal verwendet er den Datenzugriff, um eine Karte aus der DB zu holen. Das n+1-Problem besteht also immer noch, aber innerhalb unseres Backend-Servers.
Glücklicherweise kann GraphQL auch dieses Problem lösen. Es gibt ein weiteres Konzept namens DataLoader. Und hier können wir es implementieren:
public class VedaVersumCardDataLoader : BatchDataLoader<string, VedaVersumCard>
{
private readonly IVedaVersumDataAccess _vedaVersumDataAccess;
public VedaVersumCardDataLoader(
IVedaVersumDataAccess vedaVersumDataAccess,
IBatchScheduler batchScheduler,
DataLoaderOptions<string>? options = null) : base(batchScheduler, options)
{
_vedaVersumDataAccess = vedaVersumDataAccess;
}
// This method collects all CardIds during the single GraphQL query and executes database query once far all CardIds
protected override async Task<IReadOnlyDictionary<string, VedaVersumCard>> LoadBatchAsync(
IReadOnlyList<string> keys, CancellationToken cancellationToken)
{
var allCardsByIds = await _vedaVersumDataAccess.GetCardsById(keys);
return allCardsByIds.ToDictionary(c => c.Id);
}
}
Im Hintergrund kann der GraphQL-Query-Parser also alle CardIds während einer einzelnen GraphQL-Query erhalten und diesen DataLoader verwenden, um eine Batch-Datenbankabfrage auszuführen. Wenden wir diesen DataLoader auf unseren Abfrageauflöser an:
/// <summary>
/// Returns card by ID
/// </summary>
public async Task<VedaVersumCard?> GetCard(string cardId, VedaVersumCardDataLoader dataLoader)
{
return await dataLoader.LoadAsync(cardId, CancellationToken.None);
}
Jetzt können wir diese GraphQL-Abfrage noch einmal ausführen:
Und uns die Protokolle anschauen:

Es gibt nur eine einzige Batch-Abfrage. Cool, wir haben das n+1-Problem auf allen Ebenen beseitigt und der Kunde kann unsere GraphQL-API mit verschiedenen Abfragekombinationen mit optimaler Leistung nutzen.
4. Unit testing
Zu diesem Zeitpunkt hat der Backend-Service bereits seine Arbeit aufgenommen. Das ist großartig! Und während wir alles entwickelt haben, haben wir die Anwendung gestartet und geprüft, ob die Autorisierung funktioniert, ob die Persistenz funktioniert, ob Abfragen, Mutationen und Abonnements funktionieren. Und natürlich mussten wir sicherstellen, dass alle Dienste und ihre Abhängigkeiten richtig eingerichtet waren. Wir haben all diese Aktivitäten mit „Strawberry Shake“ IDE für GraphQL-Abfragen durchgeführt. Wenn wir die Benutzeroberfläche entwickeln, überprüfen wir einige UI-Aktivitäten, Benutzerszenarien und wie alles mit dem laufenden Backend zusammenarbeitet. In der Entwicklungsphase machen wir das manuell und „gelegentlich“. Wir decken nicht jedes Szenario und jeden Anwendungsfall ab. Dies wird „Smoke Testing“ genannt – nur um zu prüfen, ob die Anwendung zumindest startet und das Hauptszenario ohne gruselige Laufzeitfehler durchlaufen kann. Diese Tests garantieren jedoch nicht, dass unsere Anwendung ordnungsgemäß funktioniert und für den Produktionseinsatz bereit ist.
Bei großen Anwendungen empfiehlt es sich in der Regel, Integrationstestszenarien zu erstellen, die die gesamte Anwendungsfunktionalität abdecken. Diese Integrationstests sollten von einer anderen Person erstellt werden, nicht von demjenigen, der die Anwendung entwickelt hat. In der Regel gibt es im Team eine Rolle namens Quality Assurance Engineer, die für die Testszenarien verantwortlich ist. Integrationstests können automatisiert oder manuell für jede Entwicklungsphase durchgeführt werden. Integrationstests und Qualitätssicherung sind ein großer und wichtiger Teil des Entwicklungsprozesses. Aber das ist eine andere, lange Geschichte.
Es gibt jedoch noch einen weiteren wichtigen Teil des Entwicklungsprozesses, den Unit-Test. Dieser Teil liegt in der Verantwortung der Entwickler und sollte eng mit der Entwicklung der Hauptfunktionalität der Anwendung verbunden sein. Es ist gängige Praxis, den Prozess der testgetriebenen Entwicklung zu befolgen. Zum Beispiel haben wir in unserer Anwendung die Schnittstelle IVedaVersumDataAccess mit einigen Methoden zur Bearbeitung der Datenbank definiert. Wir haben diese Schnittstelle mit der Klasse VedaVersumDataAccess implementiert. Außerdem haben wir diese Schnittstelle in die Abfrage- und Mutationsauflöser injiziert. Wenn der Client eine Abfrage oder Mutation aufruft, wird der entsprechende Resolver eingeschaltet. Dieser Resolver sollte dann die entsprechende Datenzugriffsmethode aufrufen, die ein vorhersehbares Ergebnis zurückliefern sollte. Wir haben das Szenario für den Unit-Test bereits beschrieben. Wir können die Testmethoden schreiben, die eine Instanz der Klasse Mutation erzeugen und IVedaVersumDataAccess in diese Klasse injizieren. Aber im Unit-Test müssen wir nicht die echte Datenbank aufrufen. Wir können die reale Implementierungsklasse für den Datenzugriff durch eine Mock-Implementierung ersetzen. Und wir können diese Mock-Implementierung in der Testmethode manipulieren und prüfen, ob eine Methode mit einigen erwarteten Parametern aufgerufen wurde usw.
Daher kann ich einen Teil des Programms „abtrennen“ und ein Testszenario schreiben, das diesen bestimmten Zwischenteil unserer Anwendung überprüft. Und ich kann so viele Szenarien schreiben, wie ich brauche, um die Logik aller Klassen (oder Einheiten) abzudecken, ohne die ganzen komplizierten Abhängigkeiten zwischen verschiedenen Anwendungsmodulen zu konstruieren.
Wir haben zum Beispiel die Klasse VedaVersumMutation. Und die Datenmutationsmethode hat diesen Algorithmus:

Und um sicher zu sein, dass dieser Algorithmus richtig funktioniert, sollten wir für jeden Block in diesem Algorithmus ein Testszenario schreiben. Wie Sie sehen können, verwendet die Methode eine Datenbank und einen Abo-Senderdienst. Diese beiden Abhängigkeiten werden durch den Konstruktor in die Klasse injiziert:
public class VedaVersumMutation
{
private readonly ITopicEventSender _eventSender;
private readonly IVedaVersumDataAccess _dataAccess;
public VedaVersumMutation(ITopicEventSender eventSender, IVedaVersumDataAccess dataAccess)
{
_eventSender = eventSender;
_dataAccess = dataAccess;
}
// Code omitted for brevity
}
Um die Mutationsmethode CardAction zu testen, sollten wir ein Objekt der Klasse VedaVersumMutation erstellen und diese Methode aufrufen. Wir können aber auch Mock-Objekte von DataAccess und EventSeder anstelle von echten Objekten in die Tests einfügen, die verwendet werden, wenn das Programm im „Produktionsmodus“ läuft. Mit diesen Mock-Objekten können wir überprüfen, ob die entsprechenden Methoden mit den entsprechenden Parametern aufgerufen wurden. Daher können wir nur diesen speziellen Algorithmus testen und müssen uns nicht um die Datenbank und andere Abhängigkeiten kümmern.
Dazu habe ich ein Testprojekt erstellt, das das NUnit-Testframework und die Moq-Bibliothek zum Einrichten von Mock-Objekten verwendet. Dies kann Ihnen zeigen, wie Sie diese Methode testen können:
public class VedaVersumMutationTests
{
/// <summary>
/// Event sender mock object
/// </summary>
private Mock<ITopicEventSender> _eventsSenderMock = new Mock<ITopicEventSender>();
/// <summary>
/// DataAccess mock object
/// </summary>
private Mock<IVedaVersumDataAccess> _dataAccessMock = new Mock<IVedaVersumDataAccess>();
private VedaVersumMutation MutationClassToTest;
[SetUp]
public void Setup()
{
MutationClassToTest = new VedaVersumMutation(_eventsSenderMock.Object, _dataAccessMock.Object);
}
[Test]
public async Task ShouldCallInsertNewCardDataAccessMethodOnCardCreate()
{
// Arrange. Mocking dataAccess behavior
_dataAccessMock.Setup(d=> d.InsertNewCard(It.IsAny<string>(), It.IsAny<string>(), null, It.IsAny<User>()))
.ReturnsAsync(ExpectedCardData);
// Action
var resultCard = await MutationClassToTest.CardAction(
VedaVersumCardAction.Create,
ExpectedCardData.Title,
ExpectedCardData.Content,
relatedCards: null,
cardId: null,
TestUser);
// Assert
Assert.NotNull(resultCard);
Assert.IsNotEmpty(resultCard.Id);
Assert.AreEqual(ExpectedCardData.Title, resultCard.Title);
// Check if data accessor's InsertNewCard method has been called only once and with appropriate parameters
_dataAccessMock.Verify(d => d.InsertNewCard(
ExpectedCardData.Title,
ExpectedCardData.Content,
null,
It.IsAny<User>()
), Times.Once);
// Check if EventSender's method SendAsync has been called only once
_eventsSenderMock.Verify(s => s.SendAsync<string, CardActionMessage>(
nameof(VedaVersumSubscription.CardChanged),
It.Is<CardActionMessage>(m => m.Action == VedaVersumCardAction.Create),
It.IsAny<CancellationToken>()),
Times.Once);
}
[TestCase(VedaVersumCardAction.Update)]
[TestCase(VedaVersumCardAction.Delete)]
public void ShouldThrowExceptionIfActionIsNotCreateAndCardIdIsNull(VedaVersumCardAction action)
{
Assert.ThrowsAsync<ArgumentNullException>(() => MutationClassToTest.CardAction(
action,
ExpectedCardData.Title,
ExpectedCardData.Content,
relatedCards: null,
cardId: null,
TestUser));
}
// Other test scenarios are omitted
}
Das vollständige Testprojekt finden Sie im Repository. Jetzt können wir diese Tests mit dem Test Explorer in VS 2022 oder mit der Befehlszeile „dotnet test“ starten und sicherstellen, dass alle Tests grün sind.
Fazit
Wir haben heute mit jeder Menge Sachen gespielt. Wir haben die GraphQL-API implementiert, wir haben MongoDB als Datenpersistenz zu unserer API hinzugefügt. Wir haben uns einige coole Funktionen von GraphQL angesehen, wie Resolver und Data Loader. Schließlich haben wir einige Unit-Tests erstellt. Damit haben wir die Runde des typischen Backend-Entwicklungslebenszyklus abgeschlossen. Ich hoffe, Ihr habt unsere Reise genossen. Im nächsten Teil unserer Serie werden wir die UI-Anwendung mit React erstellen.
Bis bald!
