

1. Data persistence
As we have defined before, our API has one main entity – VedaVersumCard. Our application is intended to keep the list of knowledge cards and to grant users the ability to create, read and edit these cards. To make it happen we defined one mutation and 3 queries in our API. “CardAction” mutation should take the card data as an argument and store this data somewhere. Query “allCards” should return the list of all the existing cards. Query “card” should return one card by card ID, and “allCardsAssignedToUser” query should take user E-Mail as input and return cards filtered by property “assignedUsers” which value equals to that input user.

VedaVersum card entity
For the moment this mutation and 3 queries are not implemented and don’t do any relevant actions with our entity. Now it is time to choose which database to use for keeping our cards list. We have a lot of options here. We can use relational database like Oracle or MS SQL Server. But these are industrial giants purposed at working under high load and operate hundreds transactions per second. The lightweight SQLite is more suitable for small applications. Main advantages of SQLite are as follows:
- it’s free and open-source
- it keeps the data in a single file and doesn’t need any server to run database engine.
- dotNet has brilliant tool for working with relational databases called Entity Framework.
But from the other hand as every relational database, SQLite requires to define strongly-typed database scheme. For example, in our VedaVersum entity we can define some other properties like “Archived” flag in the future. In case of relational database this is a breaking change which requires some efforts to provide scheme migrations with already existing database. They are justified if we have rich good-structured denormalized data model which is not changing too often. But in our case VedaVersum entities it’s just a list of documents. NoSQL database is perfect database to store the lists of documents. That’s why we will use MongoDB. This is the main player in the world of NoSQL databases. It is free and open-source. It stores data as list of JSON documents and does not require strongly-typed database scheme. And it provides high performance, scaling and backup tools such as all serious databases.
2.1. Setup MongoDB
If you never used Mongo in your development machine, first you should install database engine. Here are some instructions how you can do this. I use Docker desktop on my machine and have MongoDB started as docker container.
As soon as we have MongoDB engine up and running, we can use it in our project. There is a MongoDB driver for dotNet which we will use in our project, so first we should add a Nuget package to our project.
Secondly, we should add a new parameter to our appsettings.json with the connection string.
And thirdly, we should define a new interface IVedaVersumDataAccess and VedaVersumDataAccess service which implements this interface.

2.2. Data access implementation
We have defined the data access interface with CRUD operations. We will use this interface in our mutation and queries. And here I am briefly describing the implementation of data access itself.
"ConnectionStrings": {
"mongo": "mongodb://localhost:27017"
}
public class VedaVersumDataAccess : IVedaVersumDataAccess
{
private const string DatabaseName = "VedaVersum";
private const string VedaVersumCardsCollectionName = "Cards";
private readonly IMongoDatabase _database;
public VedaVersumDataAccess(string mongoDbConnectionString, ILogger<VedaVersumDataAccess> logger)
{
var mongoConnectionUrl = new MongoUrl(mongoDbConnectionString);
var mongoClientSettings = MongoClientSettings.FromUrl(mongoConnectionUrl);
mongoClientSettings.ClusterConfigurator = cb => {
cb.Subscribe<CommandStartedEvent>(e => {
logger.LogDebug($"{e.CommandName} - {e.Command.ToJson()}");
});
};
var client = new MongoClient(mongoClientSettings);
_database = client.GetDatabase(DatabaseName);
}
/// <inheritdoc />
public async Task DeleteCard(string cardId)
{
var cardsCollection = _database.GetCollection<VedaVersumCard>(VedaVersumCardsCollectionName);
await cardsCollection.DeleteOneAsync(Builders<VedaVersumCard>.Filter.Where(c => c.Id == cardId));
}
/// <inheritdoc />
public async Task<IEnumerable<VedaVersumCard>> GetAll()
{
var cardsCollection = _database.GetCollection<VedaVersumCard>(VedaVersumCardsCollectionName);
var allCards = await cardsCollection.FindAsync(Builders<VedaVersumCard>.Filter.Empty);
return allCards.ToList();
}
// Code omitted for brevity
}
startup.cs
// DataAccess
var connectionString = Configuration.GetConnectionString("mongo");
services.AddTransient<IVedaVersumDataAccess, VedaVersumDataAccess>((p) => new VedaVersumDataAccess(
connectionString,
p.GetService<ILogger<VedaVersumDataAccess>>()!));
You can find full code in GitHub repository. As you can see, it’s pretty simple to use MongoDB in ASP.Net core application. And here are our API methos working:
Create Card:

Read All Cards:

Update card:

We have implemented data persistence in our application! Yay!
3. GraphQL resolvers and data loaders
Now it’s time to talk a little bit about data objects cross references and performance. As you have already noticed, every knowledge card has a list of related card Ids. The cards are stored in the database with this structure:
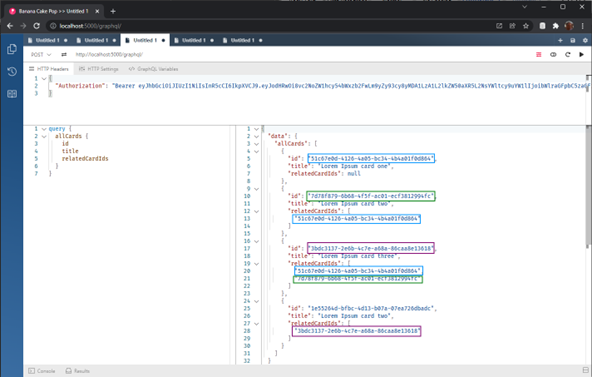
So, “card two” references the “card one”, “card three” references “cards two and one” and so on. If we are fetching all cards, maybe it’s not a big problem. But what if client app wants to request only “card three” and all its dependencies, our query will look like this:
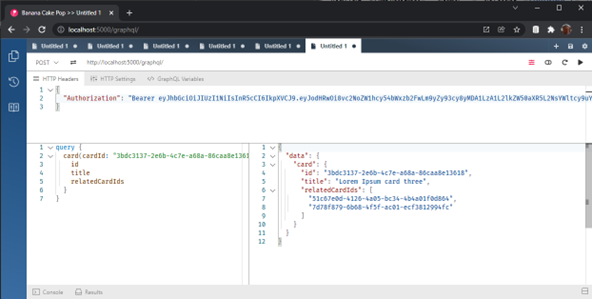
For related cards we have only Ids and to get their content the client should call the same query two more times. And if there are more than two related cards, number of requests from client to server dramatically increases. This situation is usual for REST API and called “n+1 problem”.
Fortunately, one of the GraphQL tasks is the ability to eliminate this n+1 problem. We can define some query hook called Resolver. This resolver allows client to fetch all related objects at one request. Let’s add this resolver to our GraphQL API for related cards:
public class VedaVersumCardObjectType: ObjectType<VedaVersumCard>
{
protected override void Configure(IObjectTypeDescriptor<VedaVersumCard> descriptor)
{
descriptor
.Field("relatedCards") // Name of the additional field
.Type<ListType<VedaVersumCardObjectType>>()
.Resolve(async context =>
{
var parent = context.Parent<VedaVersumCard>();
if(parent.RelatedCardIds == null || parent.RelatedCardIds.Count == 0)
{
return new List<VedaVersumCard>();
}
var dataAccess = context.Service<IVedaVersumDataAccess>();
return await dataAccess.GetCardsById(parent.RelatedCardIds);
});
}
}
This object type extends our VedaVersumCard object adding a new field to it. And implements the logic of filling this field. Now we must add this new object type definition to our GraphQL server setup at startup.cs.
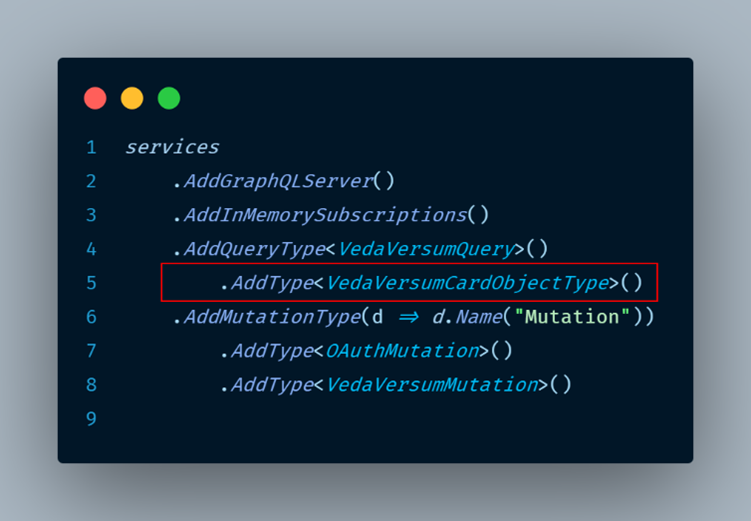
And we can run our query again:

As you could notice, there is an additional field in the query called “relatedCards”, and we can get all related cards information just using single request to GraphQL server. So, we have just got rid of our n+1 problem. Bingo!
There is one more point. GraphQL allows both to query related data by single request and to construct the query the way that the same API method can be called multiple times with different parameters but using only one request. For instance, the client application has the IDs of three cards. The client can construct the query to get the details of all 3 cards using this query:

It works perfectly. I can get any data I want without the above-mentioned n+1 problem. But if I were curious and attached a logger to the MongoDB client, I could see that GraphQL server made 3 subsequent requests to the database with that single request.

Let’s take a look again to our query method:
/// <summary>
/// Returns card by ID
/// </summary>
public async Task<VedaVersumCard?> GetCardById(string cardId)
{
return _dataAccess.GetCardById(cardId);
}
In spite of the single query to GraphQL, the resolver is executed each time for each ID. And each time it uses the data access to fetch one card from DB. So, n+1 problem still exists, but inside of our backend server.
Fortunately, GraphQL can handle this problem too. There is another concept called DataLoader. And here we can implement it:
public class VedaVersumCardDataLoader : BatchDataLoader<string, VedaVersumCard>
{
private readonly IVedaVersumDataAccess _vedaVersumDataAccess;
public VedaVersumCardDataLoader(
IVedaVersumDataAccess vedaVersumDataAccess,
IBatchScheduler batchScheduler,
DataLoaderOptions<string>? options = null) : base(batchScheduler, options)
{
_vedaVersumDataAccess = vedaVersumDataAccess;
}
// This method collects all CardIds during the single GraphQL query and executes database query once far all CardIds
protected override async Task<IReadOnlyDictionary<string, VedaVersumCard>> LoadBatchAsync(
IReadOnlyList<string> keys, CancellationToken cancellationToken)
{
var allCardsByIds = await _vedaVersumDataAccess.GetCardsById(keys);
return allCardsByIds.ToDictionary(c => c.Id);
}
}
So, under the hood the GraphQL query parser can get all CardIds during single GraphQL query and use this DataLoader to execute batch database query. Let’s apply this data Loader to our query resolver:
/// <summary>
/// Returns card by ID
/// </summary>
public async Task<VedaVersumCard?> GetCard(string cardId, VedaVersumCardDataLoader dataLoader)
{
return await dataLoader.LoadAsync(cardId, CancellationToken.None);
}
Now we can execute this GraphQL query once again:
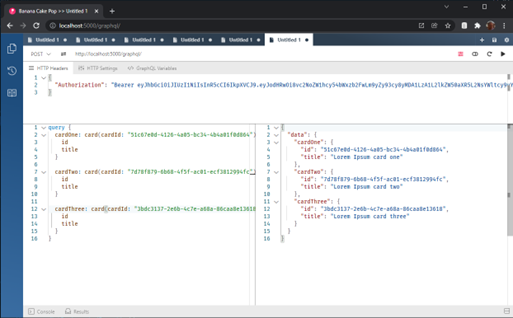
And look into the logs:

There is only one batch query. Cool, we have eliminated the n+1 problem at all levels and client can use our GraphQL API with different query combinations with optimal performance.
4. Unit testing
At this point backend service has already been put to work. That’s great! And while we were developing everything, we used to start the application and check if authorization works, if persistence works, if queries, mutations, and subscription work. And of course, we had to ensure all services and their dependencies to be properly set up. We were doing all these activities using “Strawberry Shake” IDE for GraphQL queries. When we develop UI, we will check some UI activities, user scenarios and how everything works together with backend running. At the development phase we do it manually and “occasionally”. We don’t cover every scenario and use case. This is called “smoke testing” – just to check if application starts at least and can pass main scenario without creepy run-time errors. But this testing does not guarantee our application to work properly and to be ready for production use.
For large applications it is usually recommended to construct Integration test scenarios covering the whole application functionality. These integration tests are supposed to be created by another person, not the one who developed the application. There is usually a role in the team called Quality Assurance Engineer, who is responsible for test scenarios. Integration tests can be automated or can be run manually for each development phase. Integration testing and Quality Assurance is a big and important part of the development process. But this is another long story.
But there is another important part of Development process called Unit testing. This part is the developers’ responsibility and should be closely related to the main application functionality development. There is common practice to follow Test Driven Development process. For example, we have defined IVedaVersumDataAccess interface in our application with some methods to manipulate the database. We have implemented this interface with class VedaVersumDataAccess. Also we have injected this interface to Query and Mutation resolvers. And when client calls query or mutation, the appropriate resolver will be involved. And then, this resolver should call appropriate data access method, which should return with some predictable result. We have already described the scenario for unit test. We can write the test methods which create an instance of Mutation class and inject IVedaVersumDataAccess in this class. But in unit test we don’t have to call real database. We can substitute the data access real implementation class with mock implementation. And we can manipulate this mock implementation in the test method and check if some method has been called with some expected parameters and so on.
Therefore, I can “detach” one part of the program and write test scenario checking this particular intermediate part of our application. And I can write as many scenarios as I need to cover all classes (or units) logic without constructing the whole complicated dependencies between different application modules. For example, we have the VedaVersumMutation class. And data mutating method has this algorithm:

And to be sure in this algorithm’s proper work we should write a test scenario for each block in this algorithm. As you can see, method uses Database and Subscription sender service. These two dependencies are injected into the class through the constructor:
public class VedaVersumMutation
{
private readonly ITopicEventSender _eventSender;
private readonly IVedaVersumDataAccess _dataAccess;
public VedaVersumMutation(ITopicEventSender eventSender, IVedaVersumDataAccess dataAccess)
{
_eventSender = eventSender;
_dataAccess = dataAccess;
}
// Code omitted for brevity
}
To test CardAction mutation method, we should create a VedaVersumMutation class object and call this method. But we can inject mock DataAccess and EventSeder objects instead of real objects in the tests which are used when program runs in a “production mode”. With these mock objects we can check if appropriate methods were called with appropriate parameters. Therefore, we can test only this particular algorithm and don’t care about database and other dependencies.
To do that I have created a test project which uses NUnit testing framework and Moq library for setting up mock objects. And this can show you how to test this method:
public class VedaVersumMutationTests
{
/// <summary>
/// Event sender mock object
/// </summary>
private Mock<ITopicEventSender> _eventsSenderMock = new Mock<ITopicEventSender>();
/// <summary>
/// DataAccess mock object
/// </summary>
private Mock<IVedaVersumDataAccess> _dataAccessMock = new Mock<IVedaVersumDataAccess>();
private VedaVersumMutation MutationClassToTest;
[SetUp]
public void Setup()
{
MutationClassToTest = new VedaVersumMutation(_eventsSenderMock.Object, _dataAccessMock.Object);
}
[Test]
public async Task ShouldCallInsertNewCardDataAccessMethodOnCardCreate()
{
// Arrange. Mocking dataAccess behavior
_dataAccessMock.Setup(d=> d.InsertNewCard(It.IsAny<string>(), It.IsAny<string>(), null, It.IsAny<User>()))
.ReturnsAsync(ExpectedCardData);
// Action
var resultCard = await MutationClassToTest.CardAction(
VedaVersumCardAction.Create,
ExpectedCardData.Title,
ExpectedCardData.Content,
relatedCards: null,
cardId: null,
TestUser);
// Assert
Assert.NotNull(resultCard);
Assert.IsNotEmpty(resultCard.Id);
Assert.AreEqual(ExpectedCardData.Title, resultCard.Title);
// Check if data accessor's InsertNewCard method has been called only once and with appropriate parameters
_dataAccessMock.Verify(d => d.InsertNewCard(
ExpectedCardData.Title,
ExpectedCardData.Content,
null,
It.IsAny<User>()
), Times.Once);
// Check if EventSender's method SendAsync has been called only once
_eventsSenderMock.Verify(s => s.SendAsync<string, CardActionMessage>(
nameof(VedaVersumSubscription.CardChanged),
It.Is<CardActionMessage>(m => m.Action == VedaVersumCardAction.Create),
It.IsAny<CancellationToken>()),
Times.Once);
}
[TestCase(VedaVersumCardAction.Update)]
[TestCase(VedaVersumCardAction.Delete)]
public void ShouldThrowExceptionIfActionIsNotCreateAndCardIdIsNull(VedaVersumCardAction action)
{
Assert.ThrowsAsync<ArgumentNullException>(() => MutationClassToTest.CardAction(
action,
ExpectedCardData.Title,
ExpectedCardData.Content,
relatedCards: null,
cardId: null,
TestUser));
}
// Other test scenarios are omitted
}
Full test project you can find in the repository. Now we can start these tests using Test Explorer in VS 2022 or using command line “dotnet test”, and ensure that all tests are green.
Conclusion
We have played with a lot of stuff today. We have implemented the GraphQL API, we have added MongoDB as data persistence to our API. We have looked to some cool features of GraphQL such as Resolvers and Data Loaders. Finally, we have created some unit tests. And have closed the round of typical backend development lifecycle. Hope you enjoyed our journey. In the next part of our series, we will create the UI application with React.
See you soon – Stay tuned!
