


Big Data gilt als das Trendthema der Digitalisierung. Manche behaupten sogar, Daten seien das neue Gold. Doch Nutzungsdaten sind ein bislang selten gehobener Schatz, um die Usability mit quantitativen Methoden zu analysieren. Welche Möglichkeiten gibt es, mit Nutzungsdaten UX messbar zu verbessern und Product Owner in ihren Entscheidungen zu unterstützen? Erhalten Sie einen ersten Überblick über die Analyse von Nutzungsdaten in meinem Blogartikel.
Was ist Nutzungsdatenanalyse?
Nutzungsdatenanalyse bedeutet, dass der Fokus der Analyse auf der Software und der Nutzung ihrer Features liegt, um Aussagen darüber zu treffen, ob das Konzept des Bedienungsflows erfolgreich ist und damit auf Bugs und überflüssige beziehungsweise fehlende Funktionen aufmerksam zu machen. Natürlich basieren alle Schritte im UX Prozess auf den Bedürfnissen der Nutzergruppe, aber eben nicht auf denen der einzelnen Nutzer.
Stellen Sie sich vor, Sie haben ein neues Produkt entwickelt. Ein Schwerpunkt in der Entwicklung lag auf der UX, da Sie diese im Vorhinein als kritischen Erfolgsfaktor identifiziert haben. Nun ist ein erster Prototyp des Produkts fertig und Sie möchten wissen, ob Sie Ihre UX Ziele auch erreicht haben. Ein unmittelbarer Weg dies zu tun, ist es, einen Blick in die Daten zu werfen, die entstehen, wenn ein Nutzer mit dem neuen Produkt interagiert – die Nutzungsdaten. Eine entsprechende Analyse und Interpretation wird Ihnen Einsicht in das Nutzerverhalten und den Nutzungsflow liefern. Durch Verknüpfung der Informationen mehrerer digitaler Geräte erhalten Sie eine einmalige Gesamtübersicht.
Nutzungsdatenanalyse und Datenschutz
Wichtig in diesem Kontext ist natürlich auch das Thema Datenschutz. Deshalb reden wir im UX Bereich bewusst von Nutzungsdatenanalyse und nicht von Nutzerdatenanalyse. Wie im gesamtem UX Prozess wird die Anonymisierung sowie der Datenschutz großgeschrieben. Nutzer werden zu Personas oder Nutzungsgruppen aggregiert. Demographische Daten werden nur insoweit erfasst, wie sie relevant für die Persona und Fragestellungen sind. Zum Beispiel könnte dies der Erfahrungsgrad mit einer Software sein, welcher in unterschiedlichem Nutzungsverhalten resultieren kann.
Wie unterscheidet sich der quantitative Ansatz vom bisherigen Messen des User-Erlebnisses?
Klassische Methoden
Die bisherige Evaluation von UX Komponenten in Produkten beschränkt sich oft auf eine qualitative Datenerfassung. Oft werden Nutzer bei der Bedienung des Prototyps beobachtet und befragt, um potenzielle Schwachstellen zu identifizieren. Manchmal wird dieser Konzepttest auch noch durch einen Fragebogen ergänzt, um wenigstens ein quantifizierbares Maß zu haben. Eine alleinige Nutzerbefragung kann irreführend oder unvollständig sein. In Fragebögen zeigt sich oft eine Tendenz zur Mitte in der Beantwortung der Items, man bekommt also keine klaren Aussagen. Manchmal wissen Nutzer auch nicht so genau, was sie wollen, beziehungsweise haben es schwer, das verbal zu kommunizieren. Bei der Beobachtung muss man gleichzeitig den Nutzer im Blick haben und dokumentieren, wo Schwierigkeiten auftreten oder was nicht verstanden wird, wobei schnell Dinge vergessen werden können. Das Ganze ist zeitaufwändig und begrenzt sich oft auf eine Handvoll Tests.
Nutzungsdaten als Ergänzung für eine umfassende Evaluation
Nutzungsdaten können in diesem Fall eine objektive und reliable Alternative darstellen, die zudem beliebig skalierbar ist. Sie kann nicht-invasiv erfolgen, der Nutzer wird also in seinem normalen Bedienungs-Ablauf nicht gestört und fühlt sich nicht beobachtet. Der entsprechende Data Analyst kann zu einem beliebigen Zeitpunkt auf die Daten zugreifen und sie mit Hilfe von exakten Zeitangaben mit anderen Geschehnissen oder Maschinen-Daten in Verbindung bringen. Quantifizierbare Maße können schnell abgeleitet werden, beispielsweise die Häufigkeit des Auftretens eines Fehlers und somit erheblichen Einfluss auf die Priorisierung und Entscheidungstreffung hinsichtlich der nächsten Entwicklungsschritte nehmen.
Was sind wichtige KPIs der Nutzungsdatenanlyse und wie lassen sich diese erheben?
Key Performance Indicators (KPIs) tauchen in vielen Bereichen auf. Software Ingenieure kennen sie als Zeilen an Code oder Anzahl an Bugs. Content Manager im Marketing eher als Conversion Rate oder Page Views. Im UX-Bereich unterschieden wir grundsätzlich zwei Arten an KPIS: System-Level KPIs und Story-Level KPIs.
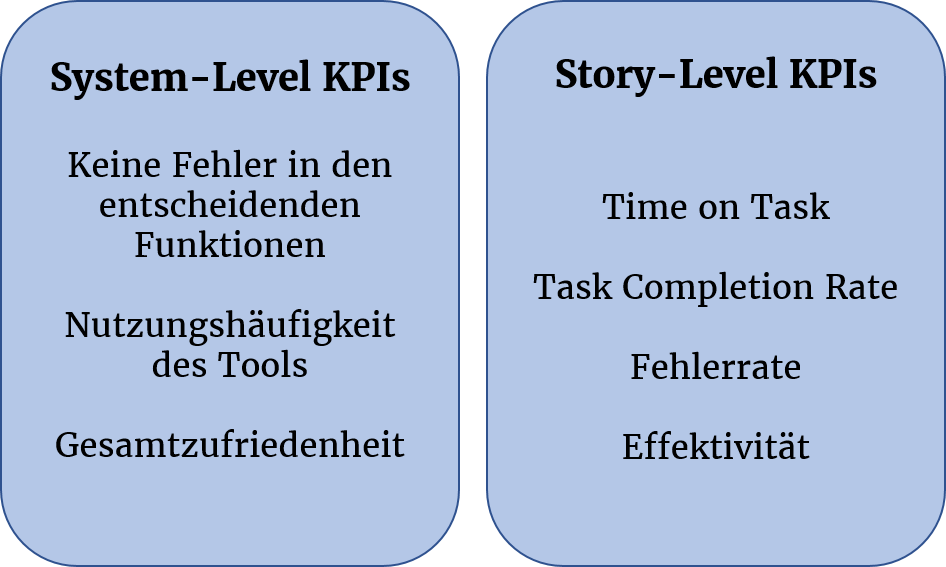
System-Level KPIs sind User Story übergreifende KPIs, die Strategie-Entscheidungen ermöglichen, jedoch keine spezifischen Produkt-Entscheidungen. Story-Level KPIs werden für jede einzelne User-Story definiert und bieten somit Entscheidungsgrundlage für einzelne Features. Die „Time on Task“ misst die Zeit, die ein User in einer Story verbringt, während die „Task Completion Rate“ beispielsweise Aufschluss darüber gibt, wie viel Prozent der Nutzer eine User Story erfolgreich verlassen haben. Für jede User-Story können dann Akzeptanzkriterien festgelegt werden, die erfüllt sein müssen, damit sie als Done gilt. Ein Runterbrechen der Komplexität der Anwendung auf User-Story Ebene sowie eine automatische Priorisierung von Problemen ermöglicht eine sukzessive Abarbeitung und lässt die Weiterentwicklung eines Produkts schnell als managable erscheinen. Ein Beispiel ist das Auftauchen einer Story im Bug Fix Pool. Beim Betrachten der Nutzungsdaten stellt sich dann heraus, dass diese Story bei keinem Nutzer aktiv war. Arbeit in das Lösen des Bugs zu stecken, wäre hier also nur Zeitverschwendung, diese Aufgabe wird keine Priorität haben.
KPIs erheben
Zur Erhebung von KPIs gibt es viele Möglichkeiten. Wie oben bereits erwähnt, gibt ein mitgeloggter Zeitstempel Einsicht in Abstände zwischen und die Dauer von Aktivitäten. Ein Mitloggen von geographischen Daten ermöglicht eine örtliche Nachverfolgung, was natürlich vor allem bei Wearables interessant ist. Alle anderen Funktionen können natürlich auch direkt in der Software verankert werden, beispielsweise die Scroll-Tiefe oder Klicks auf entsprechende UI-Elemente.
Herausforderungen des quantitativen Verfahrens
Im Laufe eines Nutzungszyklus, beispielsweise einer neuen Software, können Unmengen an Daten produziert werden. Große Datenmengen sind im Allgemeinen beliebt bei Data Scientists, bedeuten sie doch ein potenziell großes Trainingsdatenset um etwaige Modelle daran zu optimieren. Auf der anderen Seite bedeuten große Datenmengen auch immer die Gefahr des Data Dredging – dem ziellosen Fischen in großen Datenmengen bei denen basierend auf statistischem Grundrauschen immer irgendwas herauskommt, und einen entsprechenden zeitlichen Aufwand, um wirklich nützliche Informationen zu extrahieren, von der benötigten Rechenleistung mal ganz abgesehen. Und wenn Product Owner etwas oft nicht haben, dann ist es Zeit für Entscheidungen. Deshalb sollte unter allen Umständen vermieden werden zu viele Daten zu sammeln, in dem die analytischen Fragestellungen im Vorhinein klar definiert sind.
Daten können erst im Kontext sinnvoll interpretiert werden
Das alleinige Betrachten von Nutzungsdaten kann schnell den eigentlichen Nutzer samt dessen Bedürfnissen aus den Augen verlieren. Nur weil ein Flow gut aussieht, heißt das nicht, dass der Nutzer sich dabei gut abgeholt fühlt. Und was er vermisst, kann er auch nicht durch Klicken mitteilen. Deshalb ist es in der Prototyping-Phase immer sinnvoll, eine kurze Befragung oder einen Usability Fragebogen durchzuführen, um das Komplettpaket vor Augen zu haben. Wichtig ist es, die Datenanalyse als ein Tool des UX Prozesses zu sehen, das spezifisch zur Beantwortung von Fragestellungen oder Untermauerung von Annahmen verwendet wird und geschickt mit anderen Werkzeugen verknüpft wird. Erst durch diese Verknüpfung kann die Interpretation der Daten sinnvoll werden und Vertrauen in getroffene oder zu treffende Entscheidungen geben.
Nutzungsdatenanalyse und Continuous UX
Nutzungsdatenanalyse sowie -interpretation wird ein gutes Stück einfacher und präziser, wenn sie im Kontext des vorher definierten Scopes stattfindet. Dieser umfasst die Persona (repräsentativer Nutzer), die Nutzerrolle, den Nutzungskontext, Ziel und Aufgabe des Nutzers sowie die User Needs. Oft ist eine Anwendung nicht im gesamten „gut“ oder „schlecht“, Probleme treten häufig in Mikrointeraktionen auf, die dann jedoch wiederum großen Einfluss auf die Gesamt-Performance haben können. Beim Identifizieren dieser Situationen hilft das Aufsplitten in viele oft nur sekundenlange Nutzungssequenzen, die User Stories. Diese sind das zentrale Element im Continuous UX Prozess und dienen als Grundlage zur Definition der gewünschten UX KPIs. Limitiert durch die menschliche Natur können sich Nutzer zur gleichen Zeit immer nur in einer User-Story befinden, einen gesamten Nutzungsdurchlauf, die sogenannte User Journey, kann deshalb als einfacher, nicht-geschachtelter Verlauf betrachtet werden. Mehrere User Stories können also im Zusammenhang betrachtet werden und Unterbrechungen im Nutzungsverlauf einfach identifiziert werden. Deren Visualisierung ist leicht verständlich für Personen, die keinen datenwissenschaftlichen Hintergrund haben aber mit dem Nutzungskontext vertraut sind wie Product Owner oder UX Designer.
Übersicht durch User-Booklets-Methode
Durch die Verknüpfung von User Stories und Daten in sogenannten User Booklets werden Product Owner bei der Priorisierung verschiedener User Stories unterstützt und UX Researcher erlangen detailliertere Einsicht in das Nutzungsverhalten. Gleichzeitig ist ihr Einblick wesentlich repräsentativer durch die Skalierbarkeit und Präzision der digitalen, automatisierten Datenerfassung. Muster, die über Produkte oder Nutzergruppen hinweg entstehen, können leichter erkannt werden. Stellt man hier Ähnlichkeiten fest, können daraus sogar Design Prinzipien für nachfolgende Produkte abgeleitet werden, welche wiederum UX Designern das Leben erleichtern. Zusätzlich helfen Daten potenzielle „Bottlenecks“ im Nutzungsflow schneller zu erkennen.
Fazit
Nutzungsdatenanalyse bietet, wie alle Arten der Datenanalyse, das große Plus der objektiven Erkenntnisse aufgrund derer Entscheidungen für den weiteren Entwicklungsprozess getroffen werden können. Eine Quantifizierung oder Messbarkeit kann meinungsbasiertem Entscheidungstreffen entgegenwirken und führt zu rationaleren Entscheidungen.
Wir haben Ihr Interesse geweckt? Schauen Sie sich unsere passenden Leistungen an!
